LeagueSzn
WWE 2k League Tracker
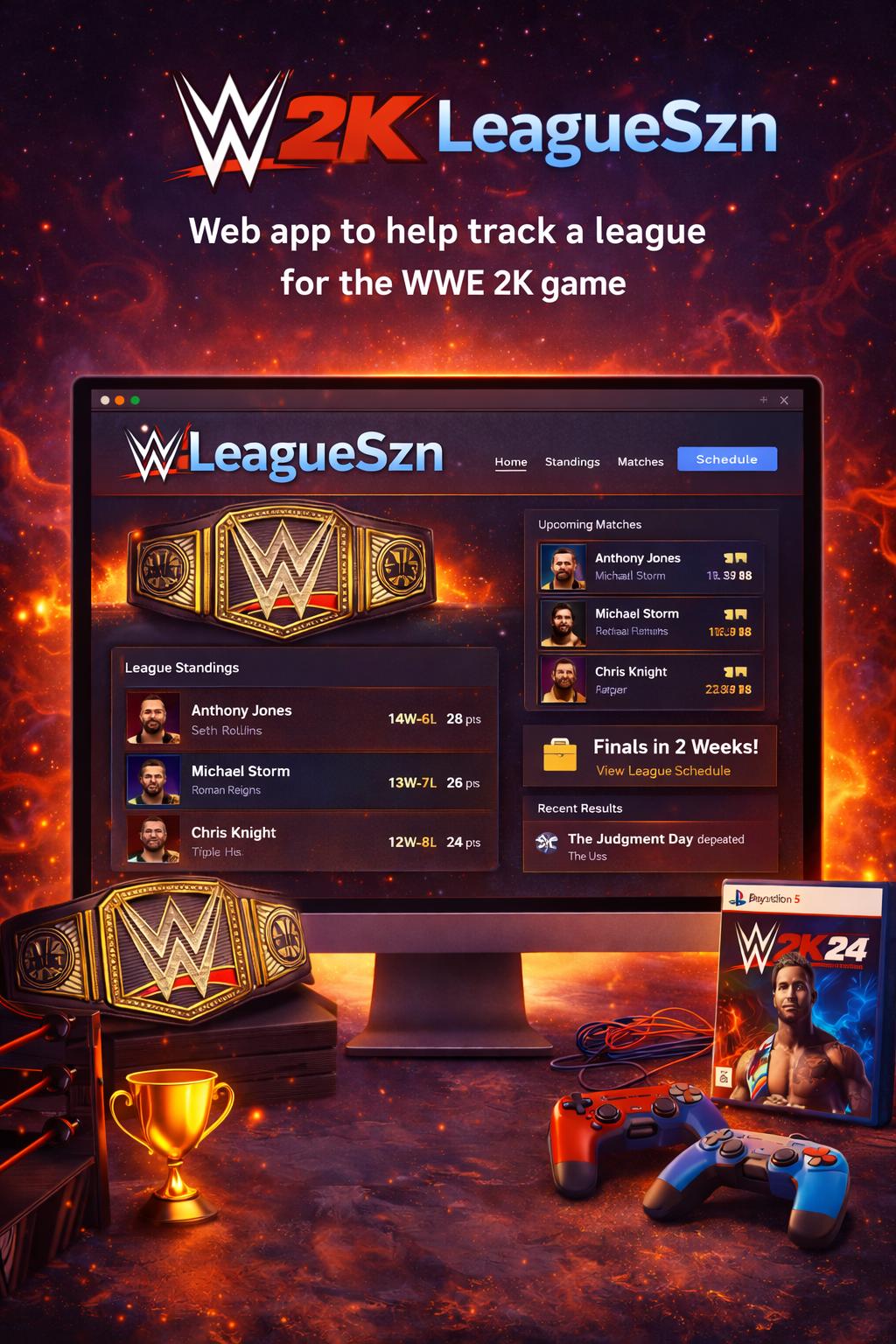
WWE 2k League Tracker
Managing a gaming league sounds simple until you actually try to build the software for it. What starts as "just a standings table" quickly spirals into transactional match result recording that cascades across seven database tables, championship reign tracking with title defense vs. title change semantics, fantasy scoring engines that run asynchronously after every event, and a role-based access system spanning four user tiers. Over the course of 535 commits across 24 days, I built the WWE 2K League Management System -- a fully serverless application handling 12+ feature domains, 19 DynamoDB tables, 1,100+ unit tests, internationalization in two languages, and multi-environment CI/CD. This post walks through the engineering decisions, the trade-offs I weighed, the patterns that emerged, and the things I would do differently next time.
Live app: leagueszn.jpdxsolo.com | Source code: github.com/jpDxsolo/league_szn

The system is fully serverless on AWS, with a React SPA served from CloudFront/S3 and a Serverless Framework backend running Lambda functions behind API Gateway.
graph TB
subgraph "Client"
Browser["React SPA<br/>TypeScript + Vite"]
end
subgraph "CDN & Hosting"
CF["CloudFront CDN<br/>HTTPS + SPA Routing"]
S3_FE["S3 Bucket<br/>Static Assets"]
end
subgraph "Authentication"
Cognito["AWS Cognito<br/>User Pool + Groups"]
end
subgraph "API Layer"
APIGW["API Gateway<br/>REST API + CORS"]
Auth["Lambda Authorizer<br/>JWT Validation"]
end
subgraph "Compute"
Lambda["Lambda Functions<br/>~12 Domain Handlers"]
AsyncLambda["Async Lambdas<br/>Fantasy Scoring<br/>Ranking Recalculation"]
end
subgraph "Data"
DDB["DynamoDB<br/>19 Tables<br/>Pay-per-Request"]
S3_IMG["S3 Bucket<br/>Player & Belt Images"]
end
subgraph "CI/CD"
GHA["GitHub Actions<br/>Dev + Prod Pipelines"]
end
Browser --> CF
CF --> S3_FE
Browser --> Cognito
Browser --> APIGW
APIGW --> Auth
Auth --> Cognito
APIGW --> Lambda
Lambda --> DDB
Lambda --> S3_IMG
Lambda --> AsyncLambda
AsyncLambda --> DDB
GHA --> S3_FE
GHA --> LambdaEvery public page -- standings, championships, events, tournaments -- is accessible without authentication. Admin operations (match scheduling, result recording, player management) require a JWT token validated by a custom Lambda authorizer. The frontend conditionally attaches the Authorization header through a single fetchWithAuth function, so the same API client code handles both public and protected endpoints.
This was the first architectural decision, and it shaped everything that followed. For a league management app with bursty traffic (heavy during match nights, near-zero otherwise), serverless made strong economic and operational sense.
The calculus: An always-on EC2 instance or ECS service costs around $15-30/month even at idle. DynamoDB on-demand billing and Lambda's free tier mean the entire backend runs at effectively zero cost during low-traffic periods. For a hobby project that needs to stay deployed indefinitely, the difference between $0 and $20/month is the difference between "keep it running forever" and "shut it down after the portfolio review."
The trade-off: Cold starts. Lambda functions behind API Gateway can take 500ms-2s on first invocation. I mitigated this by consolidating from 40+ individual Lambda functions down to ~12 domain-routed handlers. Each domain handler (players, matches, championships) uses a lightweight switch on HTTP method and path to dispatch to the correct function. Fewer functions means fewer cold starts, and each function stays warm longer because it handles more request types.
This is the decision I get asked about most. Relational databases are the default choice -- they handle complex queries naturally, enforce referential integrity, and most developers know SQL. So why DynamoDB?
Argument for DynamoDB: Every entity in this system has a clear access pattern. Players are looked up by ID. Matches are queried by partition key with optional date sorting. Season standings are keyed on (seasonId, playerId). Championship history queries by (championshipId, wonDate). These are all single-table key-value access patterns where DynamoDB excels, returning results in single-digit milliseconds with zero connection management.
Argument against: The match search feature required scanning with multiple filter expressions -- match type, stipulation, player, date range, season. In PostgreSQL, this would be a straightforward WHERE clause with indexed columns. In DynamoDB, it requires either a full scan with filters (acceptable at our data volume) or careful GSI design.
What tipped the decision: Zero administration. No connection pooling configuration, no RDS instance to right-size, no storage autoscaling to configure. For a solo developer moving fast across 12 feature domains, removing operational overhead was worth the query flexibility trade-off.
The authentication system went through four distinct iterations, which is worth discussing because it shows how requirements evolve:
AuthContext exposes role-checking helpers.The role hierarchy is implemented with a single hasRole function that respects the inheritance chain:
const hasRole = useCallback((role: UserRole): boolean => {
if (state.groups.includes('Admin')) return true;
if (state.groups.includes('Moderator') && role !== 'Admin') return true;
return state.groups.includes(role);
}, [state.groups]);Admins can do everything. Moderators can do everything except user management. This pattern avoided a complex permissions table -- role membership is the permission.
The most complex handler in the system is recordResult.ts at 652 lines. Recording a match result is not just updating one row -- it cascades across multiple tables atomically:
scheduled to completed (with optimistic locking via a version field)Steps 1-3 execute inside a DynamoDB TransactWrite for atomicity. Championship and tournament updates run as separate transactions to stay within DynamoDB's 100-item transaction limit. The async invocations use fire-and-forget InvocationType: 'Event' to keep the response latency low:
export async function invokeAsync(
functionName: string,
payload?: Record<string, unknown>,
): Promise<void> {
const fullName = `${SERVICE_NAME}-${STAGE}-${functionName}`;
const command = new InvokeCommand({
FunctionName: fullName,
InvocationType: 'Event',
Payload: payload ? Buffer.from(JSON.stringify(payload)) : undefined,
});
const response = await lambda.send(command);
if (response.StatusCode !== 202) {
throw new Error(`Async invocation of ${fullName} returned status ${response.StatusCode}`);
}
}This decomposition keeps the critical path fast (match + standings update) while offloading expensive recalculations to background workers.

Every Lambda response passes through a shared response module that attaches security headers by default. This means HSTS, X-Frame-Options, and X-Content-Type-Options are never forgotten on a per-handler basis:
const headers = {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': process.env.ALLOWED_ORIGIN || 'https://leagueszn.jpdxsolo.com',
'X-Content-Type-Options': 'nosniff',
'X-Frame-Options': 'DENY',
'Strict-Transport-Security': 'max-age=63072000; includeSubDomains; preload',
};
export const success = (data: any): APIGatewayProxyResult => ({
statusCode: 200, headers, body: JSON.stringify(data),
});
export const badRequest = (message: string) => error(400, message);
export const notFound = (message: string = 'Resource not found') => error(404, message);This is a small pattern, but it eliminated an entire class of bugs -- inconsistent CORS headers, missing security headers, and non-JSON error responses.
After building 20+ create handlers that all followed the same pattern (parse body, validate required fields, generate UUID, insert into DynamoDB, return 201), I extracted a factory function:
export function handlerFactory(options: CreateHandlerOptions): APIGatewayProxyHandler {
return async function(event) {
const { data: body, error: parseError } = parseBody(event);
if (parseError) return parseError;
const missing = options.requiredFields.filter(field => !body[field]);
if (missing.length > 0) return badRequest(`${missing.join(', ')} are required`);
if (options.validate) {
const validateError = await options.validate(body, event);
if (validateError) return validateError;
}
const item = { [options.idField]: uuidv4(), createdAt: new Date().toISOString(), ...body };
await dynamoDb.put({ TableName: options.tableName, Item: item });
return created(item);
};
}A create handler that used to be 30+ lines becomes a configuration object. The factory handles body parsing, validation, ID generation, timestamps, and error handling uniformly. Eleven unit tests verify the factory's behavior for required field validation, custom validators, optional fields, and error paths.
The frontend API client started as a single api.ts file. By the time events, fantasy, challenges, promos, and statistics were added, it had grown to 650+ lines. This is a common pattern in fast-moving projects: you start with one file because it is convenient, and you refactor when the friction becomes undeniable.
The split preserved backward compatibility through a barrel export -- existing imports continued to work while new code could import from feature-specific modules (services/api/players.ts, services/api/matches.ts, etc.).
The backend started with one Lambda function per HTTP endpoint. At 40+ functions, serverless.yml had over 1,400 lines of function definitions, cold starts were frequent because traffic was spread across too many functions, and deployment took increasingly long.
The consolidation was done in three phases to manage risk: simple CRUD domains first (divisions, stipulations), then medium-complexity domains (players, championships), then the complex handlers (matches with recordResult). Each domain got a router that dispatches based on HTTP method and resource path. The result: fewer cold starts, simpler configuration, and faster deployments.
The UI navigation went through a revealing evolution:
Each iteration was a response to real usability feedback, not premature optimization. This is the kind of pragmatic iteration that production projects demand.

GitHub Actions powers two deployment pipelines:
main trigger deploy-dev.yml: lint, typecheck, test, deploy backend to devtest stage, build frontend with dev environment variables, sync to the dev S3 bucket.deploy-prod.yml: same validation steps, deploy to production stage, sync to production S3 bucket, invalidate the CloudFront cache.The dev environment has its own API Gateway endpoint, DynamoDB tables (with a devtest suffix), and S3 bucket. This means every PR gets a full integration test against a real AWS stack before it touches production.
A subtle problem with hosting SPAs on S3: if a user navigates to /standings and refreshes the page, S3 returns a 404 because no file exists at that path. CloudFront solves this with custom error responses that redirect 403 and 404 errors to /index.html, letting React Router handle client-side routing.
Every AWS resource -- 19 DynamoDB tables, the Cognito User Pool, S3 buckets, CloudFront distributions, IAM roles, API Gateway configuration -- is defined in serverless.yml. There is no manual console configuration. This means the entire infrastructure can be torn down and rebuilt from a single serverless deploy command, and every change is version-controlled.

The project reached 1,100+ unit tests across backend and frontend:
__tests__ directory. Tests mock DynamoDB operations and verify input validation, error handling, and response shapes.A comprehensive code review in Phase 7 also addressed systemic issues: JSON.parse without try-catch (which crashes Lambda on malformed input), missing AbortController cleanup in React effects (memory leak potential), and inconsistent error response formats.

Start with a data access layer abstraction sooner. The getOrNotFound and buildUpdateExpression utilities were extracted late in the project (Phase 12). Every handler before that had its own inline DynamoDB boilerplate -- get item, check if null, return 404. Extracting these patterns earlier would have saved significant duplication.
Adopt single-table design for DynamoDB. With 19 tables, I am using DynamoDB more like a relational database with one table per entity. A single-table design with composite keys and GSIs would reduce the number of table references, simplify IAM policies, and enable transactional operations across what are currently separate tables. The trade-off is increased query complexity and a steeper learning curve for the data model.
Invest in E2E tests earlier. Playwright was set up in Phase 3 but never fully utilized. The 1,100+ unit tests verify individual components and handlers, but they do not catch integration issues like "the frontend sends a field name the backend does not expect." A small suite of happy-path E2E tests would have caught several bugs that unit tests missed.
Use a monorepo tool. The project has separate package.json files for frontend and backend with no shared types between them. TypeScript interfaces are duplicated. A tool like Turborepo or Nx with shared type packages would enforce type consistency across the stack.
Rate limiting and monitoring. The API has no rate limiting beyond what API Gateway provides by default, and there is no structured monitoring or alerting. For a production system serving real users, CloudWatch alarms on Lambda errors and API Gateway 5xx rates would be table stakes.
The final system delivers:


The system manages the complete lifecycle of a gaming league: creating players, scheduling matches within events and seasons, recording results with automatic standings updates, tracking championship reigns and title defenses, running single-elimination and round-robin tournaments, computing fantasy scores, surfacing rivalries and statistics, and providing a self-service wiki for league participants.
Building it reinforced a principle I keep coming back to: the hard part of software engineering is rarely the individual feature. It is the interactions between features -- how recording a match result needs to update standings, championships, tournaments, events, fantasy scores, and contender rankings atomically and efficiently. Getting that right requires careful system design, and getting it wrong creates the kind of subtle data inconsistency bugs that erode user trust.
Try the live app: leagueszn.jpdxsolo.com | Read the code: github.com/jpDxsolo/league_szn